Tidy Text Mining
OCRUG Hackathon 2023
Schedule
09:30 AM – 10:15 AM: Text Mining10:15 AM - 10:30 AM: Break10:30 AM - 11:15 AM: Modeling with Text
What is text mining?
What is text?
What is text?
A series of characters, hopefully trying to convey meaning
If you don’t go to other men’s funerals, they won’t go to yours.
猿も木から落ちる
See you soon 🛫🌴🌞
What is text mining?
The process of transforming unstructured text into structured data for easy analysis
Disclaimer
I’ll show examples in English
English is not the only language out there #BenderRule
The difficulty of different tasks vary from language to language
langauge != text
Software
![]()
- tidytext
- quanteda
- tm
![]()
- NLTK
- spacy


Most of data science
is counting,
and sometimes dividing
Hadley Wickham
Most of data science
text preprocessing
is counting,
and sometimes dividing
Hadley Wickham Emil Hvitfeldt
Plan
- tokenize
- modify tokens
- remove tokens
- count tokens
Data
Data - decision year
We are only looking at 2 different years: 2022 and 2012

Data - amount
The money about of the grant is quite varied

Data - amount
Even once we take the logarithm

Data - abstracts
[1] "In organizational research, corruption, the misuse of a position of authority by actors within organizations for private or organizational gain, has attracted a wealth of scholarship (e.g. Ashforth & Anand, 2003; Castro et al., 2020; Greve et al., 2010; Pinto et al., 2008). Since corruption is a type of misconduct which creates vastly nega-tive consequences, understanding how it can be averted and controlled has been an important research focus (e.g. Lange, 2008; Misangyi et al., 2008). This scholarship points to the critical role of anti-corruption regulation. Hereby, regulation can be generally defined as activity that aims at “prevent[ing] the occurrence of certain un-desirable activities” among targeted actors, such as organizations or individuals (Baldwin et al., 2012: 3).Research on organizational anti-corruption regulation has several shortcomings. First, it focuses either on public or on private anti-corruption regulation (e.g. Hough, 2013) thus tending to explore either the regulato-ry activities of public authorities and focusing predominantly on mandatory regulatory pressures or exploring private actors who assume quasi-regulatory roles and use voluntary regulatory tools. There is a lack of under-standing of how public and private anti-corruption regulation interrelate and under which conditions they yield “synergistic effects” in inducing targeted actors to behave in desirable ways (e.g. Aragon-Correa et al., 2020: 353). Second, our understanding of how public and private anti-corruption regulation interrelate in the context of international nongovernmental organizations (INGOs) is particularly scarce. INGOs are rule-making bodies in a variety of global sectors, including sports organizations, scientific bodies, religious groups, or medical special-ists (Boli & Thomas, 1999). Although corruption may be wide-spread also among INGOs (Transparency Inter-national, 2012), INGOs have predominantly been conceived as communities that regulate themselves (e.g. Boli & Thomas, 1999) rather than as the target of regulatory pressure that public and private regulators levy against them. To address these gaps, we propose to conduct systematic exploratory research with a focus on Interna-tional Sports Federations (ISF), a field of INGOs where corruption has been a particularly pertinent issue. ISFs serve as revelatory cases for our theory building (Yin, 2014). While they have faced regulatory pressure from public and private regulators, ISF scholarship has predominantly focused on self-regulatory measures (Chap-pelet, 2017; Chatzigianni, 2018; Forster, 2016; Geeraert, 2019; Pieth, 2014). As a consequence, we do not know enough about how the interaction of public and private anti-corruption regulation has influenced the behavior of ISFs.In our analysis of the ISF context, we will draw on the smart regulation approach (e.g. Gunningham et al., 1998). Smart regulation is a normative theory emphasizing that the combination of multiple regulatory in-struments and the coordination of public and private regulatory actors will yield better regulatory outcomes. In view of the smart regulation approach, our project has two purposes: First, we aim to rely on the ‘regulatory design principles’ underlying the smart regulation approach as yardsticks for detailed empirical research in the ISF field. The aim is to inductively develop new descriptive theory on interrelationships between public and private anti-corruption regulation in an INGO context. Second, we will also build new normative theory1: We will build on our empirical findings in order to adapt these design principles to the ISF context and explore how anti-corruption regulation in a field of INGOs where corruption has been a pertinent issue should look like.We contribute to different literature streams including scholarship on organizational corruption, regula-tory scholarship, neo-institutional organization theory, global governance, and international sports federations."Data - abstracts

Tokenization
What is tokenization?
The process of turning raw text into tokens
What are tokens?
a meaningful unit of text, such as a word
Example text
[1] "The bicycle as an example of social construction - Cycling in Eastern Europe: why are we surprised to learn about its history? - Micromobility and state policies - Bicycle for emancipation and as a means of totalitarian control - How does history cycling in Eastern Europe relate to other global phenomena of cycling?"White spaces tokenization
"The" "bicycle" "as" "an" "example" "of" "social" "construction" "-" "Cycling" "in" "Eastern" "Europe:" "why" "are" "we" "surprised" "to" "learn" "about" "its" "history?" "-" "Micromobility" "and" "state" "policies" "-" "Bicycle" "for" "emancipation" "and" "as" "a" "means" "of" "totalitarian" "control" "-" "How" "does" "history" "cycling" "in" "Eastern" "Europe" "relate" "to" "other" "global" "phenomena" "of" "cycling?"{tokenizers} package
"the" "bicycle" "as" "an" "example" "of" "social" "construction" "cycling" "in" "eastern" "europe" "why" "are" "we" "surprised" "to" "learn" "about" "its" "history" "micromobility" "and" "state" "policies" "bicycle" "for" "emancipation" "and" "as" "a" "means" "of" "totalitarian" "control" "how" "does" "history" "cycling" "in" "eastern" "europe" "relate" "to" "other" "global" "phenomena" "of" "cycling"tokenization considerations
- Should we turn UPPERCASE letters to lowercase?
- How should we handle punctuation?
- What about non-word characters inside words?
Plan
- cleaning text
- tokenize
- modify tokens
- remove tokens
- count tokens
Cleaning
Very manual process, and will be highly domain-specific
You might have to use 👻Regular Expressions🧛
Cleaning
Some grant have many references:
Cleaning
[1] "In organizational research, corruption, the misuse of a position of authority by actors within organizations for private or organizational gain, has attracted a wealth of scholarship (e.g. Ashforth & Anand, 2003; Castro et al., 2020; Greve et al., 2010; Pinto et al., 2008). Since corruption is a type of misconduct which creates vastly nega-tive consequences, understanding how it can be averted and controlled has been an important research focus (e.g. Lange, 2008; Misangyi et al., 2008). This scholarship points to the critical role of anti-corruption regulation. Hereby, regulation can be generally defined as activity that aims at “prevent[ing] the occurrence of certain un-desirable activities” among targeted actors, such as organizations or individuals (Baldwin et al., 2012: 3).Research on organizational anti-corruption regulation has several shortcomings. First, it focuses either on public or on private anti-corruption regulation (e.g. Hough, 2013) thus tending to explore either the regulato-ry activities of public authorities and focusing predominantly on mandatory regulatory pressures or exploring private actors who assume quasi-regulatory roles and use voluntary regulatory tools. There is a lack of under-standing of how public and private anti-corruption regulation interrelate and under which conditions they yield “synergistic effects” in inducing targeted actors to behave in desirable ways (e.g. Aragon-Correa et al., 2020: 353). Second, our understanding of how public and private anti-corruption regulation interrelate in the context of international nongovernmental organizations (INGOs) is particularly scarce. INGOs are rule-making bodies in a variety of global sectors, including sports organizations, scientific bodies, religious groups, or medical special-ists (Boli & Thomas, 1999). Although corruption may be wide-spread also among INGOs (Transparency Inter-national, 2012), INGOs have predominantly been conceived as communities that regulate themselves (e.g. Boli & Thomas, 1999) rather than as the target of regulatory pressure that public and private regulators levy against them. To address these gaps, we propose to conduct systematic exploratory research with a focus on Interna-tional Sports Federations (ISF), a field of INGOs where corruption has been a particularly pertinent issue. ISFs serve as revelatory cases for our theory building (Yin, 2014). While they have faced regulatory pressure from public and private regulators, ISF scholarship has predominantly focused on self-regulatory measures (Chap-pelet, 2017; Chatzigianni, 2018; Forster, 2016; Geeraert, 2019; Pieth, 2014). As a consequence, we do not know enough about how the interaction of public and private anti-corruption regulation has influenced the behavior of ISFs.In our analysis of the ISF context, we will draw on the smart regulation approach (e.g. Gunningham et al., 1998). Smart regulation is a normative theory emphasizing that the combination of multiple regulatory in-struments and the coordination of public and private regulatory actors will yield better regulatory outcomes. In view of the smart regulation approach, our project has two purposes: First, we aim to rely on the ‘regulatory design principles’ underlying the smart regulation approach as yardsticks for detailed empirical research in the ISF field. The aim is to inductively develop new descriptive theory on interrelationships between public and private anti-corruption regulation in an INGO context. Second, we will also build new normative theory1: We will build on our empirical findings in order to adapt these design principles to the ISF context and explore how anti-corruption regulation in a field of INGOs where corruption has been a pertinent issue should look like.We contribute to different literature streams including scholarship on organizational corruption, regula-tory scholarship, neo-institutional organization theory, global governance, and international sports federations."Cleaning - removing
We can remove them with a regex
Cleaning - removing
[1] "In organizational research, corruption, the misuse of a position of authority by actors within organizations for private or organizational gain, has attracted a wealth of scholarship . Smart regulation is a normative theory emphasizing that the combination of multiple regulatory in-struments and the coordination of public and private regulatory actors will yield better regulatory outcomes. In view of the smart regulation approach, our project has two purposes: First, we aim to rely on the ‘regulatory design principles’ underlying the smart regulation approach as yardsticks for detailed empirical research in the ISF field. The aim is to inductively develop new descriptive theory on interrelationships between public and private anti-corruption regulation in an INGO context. Second, we will also build new normative theory1: We will build on our empirical findings in order to adapt these design principles to the ISF context and explore how anti-corruption regulation in a field of INGOs where corruption has been a pertinent issue should look like.We contribute to different literature streams including scholarship on organizational corruption, regula-tory scholarship, neo-institutional organization theory, global governance, and international sports federations."Cleaning - replacing
We can also undo abbreviations
Cleaning - replacing
[1] "In organizational research, corruption, the misuse of a position of authority by actors within organizations for private or organizational gain, has attracted a wealth of scholarship . Smart regulation is a normative theory emphasizing that the combination of multiple regulatory in-struments and the coordination of public and private regulatory actors will yield better regulatory outcomes. In view of the smart regulation approach, our project has two purposes: First, we aim to rely on the ‘regulatory design principles’ underlying the smart regulation approach as yardsticks for detailed empirical research in the Importer Security Filing field. The aim is to inductively develop new descriptive theory on interrelationships between public and private anti-corruption regulation in an International non-governmental organizations context. Second, we will also build new normative theory1: We will build on our empirical findings in order to adapt these design principles to the Importer Security Filing context and explore how anti-corruption regulation in a field of International non-governmental organizationss where corruption has been a pertinent issue should look like.We contribute to different literature streams including scholarship on organizational corruption, regula-tory scholarship, neo-institutional organization theory, global governance, and international sports federations."tokenizing with tidytext
{tidytext} provides many unnest_*() functions to help us to tokenize
tokenizing with tidytext
# A tibble: 1,542,649 × 4
token amount decision_year grant_number
<chr> <int> <fct> <chr>
1 in 40380800 2022 212921
2 organizational 40380800 2022 212921
3 research 40380800 2022 212921
4 corruption 40380800 2022 212921
5 the 40380800 2022 212921
6 misuse 40380800 2022 212921
7 of 40380800 2022 212921
8 a 40380800 2022 212921
9 position 40380800 2022 212921
10 of 40380800 2022 212921
# ℹ 1,542,639 more rowsModifying Tokens
Modifying Tokens
now that we have created the tokens, we will sometimes want to modify them to better reflect what they are trying to represent
In the end, we want to count the tokens, so the difference between “cow” and “cows” might not matter much
Stemming
Removing endings to words
Can be simple -> remove ending s
Can be more complicated -> porter stemmer
Tends to be quite fast
| Original word | Remove S | Plural endings | Porter stemming |
|---|---|---|---|
| colonies | colonie | colony | coloni |
| studies | studie | study | studi |
| surprisingly | surprisingly | surprisingly | surprisingli |
| distinctive | distinctive | distinctive | distinct |
| building | building | building | build |
| animals | animal | animal | anim |
| significance | significance | significance | signific |
| beaver | beaver | beaver | beaver |
stemming with tidytext
The {snowballC} package can perform the porter stemmer
stemming with tidytext
# A tibble: 1,542,649 × 5
token token_stem amount decision_year grant_number
<chr> <chr> <int> <fct> <chr>
1 in in 4.04e7 2022 212921
2 organizational organiz 4.04e7 2022 212921
3 research research 4.04e7 2022 212921
4 corruption corrupt 4.04e7 2022 212921
5 the the 4.04e7 2022 212921
6 misuse misus 4.04e7 2022 212921
7 of of 4.04e7 2022 212921
8 a a 4.04e7 2022 212921
9 position posit 4.04e7 2022 212921
10 of of 4.04e7 2022 212921
# ℹ 1,542,639 more rowsReducing number of tokens
Stemming always produces fewer unique tokens
Reducing number of tokens
We can investigate the most common token_stem
Reducing number of tokens
# A tibble: 53,774 × 3
token token_stem n
<chr> <chr> <int>
1 generally gener 25
2 generated gener 25
3 general gener 25
4 generative gener 25
5 generate gener 25
6 generation gener 25
7 generates gener 25
8 generic gener 25
9 generating gener 25
10 generalized gener 25
11 generalize gener 25
12 generalizing gener 25
13 generations gener 25
14 generous gener 25
15 generalization gener 25
16 generalizes gener 25
17 generalizations gener 25
18 generality gener 25
19 generalities gener 25
20 generator gener 25
21 generational gener 25
22 generators gener 25
23 generously gener 25
24 generalism gener 25
25 generalizers gener 25
26 communities commun 17
27 community commun 17
28 communicative commun 17
29 communicate commun 17
30 communication commun 17
31 communalism commun 17
32 communicated commun 17
33 commun commun 17
34 communications commun 17
35 communicating commun 17
36 communal commun 17
37 commune commun 17
38 communicators commun 17
39 communicates commun 17
40 communes commun 17
41 communicator commun 17
42 communism commun 17
43 adapt adapt 16
44 adaptations adapt 16
45 adaptive adapt 16
46 adaptation adapt 16
47 adapted adapt 16
48 adaptively adapt 16
49 adaption adapt 16
50 adapting adapt 16
51 adapter adapt 16
52 adapts adapt 16
53 adaptability adapt 16
54 adaptable adapt 16
55 adaptions adapt 16
56 adaptative adapt 16
57 adaptivity adapt 16
58 adapters adapt 16
59 activity activ 15
60 activities activ 15
61 activated activ 15
62 activate activ 15
63 activating activ 15
64 actively activ 15
65 active activ 15
66 activation activ 15
67 activates activ 15
68 activator activ 15
69 activism activ 15
70 activators activ 15
71 activeness activ 15
72 activ activ 15
73 activations activ 15
74 initial initi 15
75 initiation initi 15
76 initiating initi 15
77 initiatives initi 15
78 initiative initi 15
79 initiated initi 15
80 initially initi 15
81 initiates initi 15
82 initiate initi 15
83 initiator initi 15
84 initialization initi 15
85 initialized initi 15
86 initials initi 15
87 initiators initi 15
88 initialize initi 15
89 integrate integr 15
90 integrating integr 15
91 integral integr 15
92 integration integr 15
93 integrated integr 15
94 integrative integr 15
95 integrity integr 15
96 integrable integr 15
97 integrators integr 15
98 integrates integr 15
99 integrations integr 15
100 integrator integr 15
101 integrals integr 15
102 integrally integr 15
103 integrability integr 15
104 organizations organ 15
105 organization organ 15
106 organized organ 15
107 organism organ 15
108 organ organ 15
109 organic organ 15
110 organizing organ 15
111 organize organ 15
112 organisms organ 15
113 organs organ 15
114 organizes organ 15
115 organically organ 15
116 organizer organ 15
117 organics organ 15
118 organizers organ 15
119 function function 14
120 functional function 14
121 functions function 14
122 functionally function 14
123 functioning function 14
124 functionality function 14
125 functionals function 14
126 functionalities function 14
127 functionalized function 14
128 functionalization function 14
129 functionalizations function 14
130 functionalize function 14
131 functioned function 14
132 functionalism function 14
133 informed inform 14
134 inform inform 14
135 information inform 14
136 informative inform 14
137 informal inform 14
138 informational inform 14
139 informs inform 14
140 informing inform 14
141 informalization inform 14
142 informations inform 14
143 informalized inform 14
144 informant inform 14
145 informants inform 14
146 informally inform 14
147 operative oper 14
148 operational oper 14
149 operation oper 14
150 operating oper 14
151 operate oper 14
152 operates oper 14
153 operations oper 14
154 operated oper 14
155 operatively oper 14
156 operator oper 14
157 operators oper 14
158 operable oper 14
159 operant oper 14
160 operability oper 14
161 conformational conform 13
162 conformation conform 13
163 conformations conform 13
164 conformality conform 13
165 conformal conform 13
166 conforming conform 13
167 conformers conform 13
168 conform conform 13
169 conforms conform 13
170 conformally conform 13
171 conformance conform 13
172 conformity conform 13
173 conformer conform 13
174 continue continu 13
175 continuous continu 13
176 continuation continu 13
177 continues continu 13
178 continuing continu 13
179 continuously continu 13
180 continued continu 13
181 continual continu 13
182 continuities continu 13
183 continuity continu 13
184 continually continu 13
185 continuations continu 13
186 continuatively continu 13
187 cooperation cooper 13
188 cooperate cooper 13
189 cooperative cooper 13
190 cooperating cooper 13
191 cooperators cooper 13
192 cooperativity cooper 13
193 cooperations cooper 13
194 cooperativities cooper 13
195 cooper cooper 13
196 cooperatives cooper 13
197 cooperates cooper 13
198 coopers cooper 13
199 cooperatively cooper 13
200 international intern 13
# ℹ 53,574 more rowsFiltering Tokens
Counting Tokens
Now that we have the tokens in the state we want, we might want to count them
Counting Tokens
# A tibble: 53,774 × 2
token n
<chr> <int>
1 the 92058
2 of 68818
3 and 59441
4 to 40648
5 in 38999
6 a 25578
7 will 15433
8 is 15158
9 for 14918
10 on 12392
11 with 11310
12 as 11001
13 this 10779
14 that 10680
15 be 10355
16 by 9211
17 are 8841
18 we 8825
19 from 5920
20 project 5660
21 at 5479
22 an 5449
23 research 5112
24 which 4935
25 these 4859
26 or 4836
27 have 4477
28 their 4079
29 it 3815
30 has 3654
31 our 3622
32 can 3304
33 new 3242
34 such 3233
35 study 3108
36 data 2950
37 between 2829
38 also 2821
39 based 2770
40 how 2758
41 been 2646
42 well 2505
43 different 2499
44 i 2483
45 not 2451
46 cell 2397
47 high 2281
48 two 2281
49 cells 2277
50 using 2206
# ℹ 53,724 more rowsStop words
These words are not super interesting, so while we can count them, they don’t tell us much
These types of words are called stop words
I have a great talk all about stopwords here
Stop words
I define stop words as
Low information words that contribute little value to the task at hand
Stop words lists
- Galago (forumstop)
- EBSCOhost
- CoreNLP (Hardcoded)
- Ranks NL (Google)
- Lucene, Solr, Elastisearch
- MySQL (InnoDB)
- Ovid (Medical information services)
- Bow (libbow, rainbow, arrow, crossbow)
- LingPipe
- Vowpal Wabbit (doc2lda)
- Text Analytics 101
- LexisNexis®
- Okapi (gsl.cacm)
- TextFixer
- DKPro
Stop words lists
- Postgres
- CoreNLP (Acronym)
- NLTK
- Spark ML lib
- MongoDB
- Quanteda
- Ranks NL (Default)
- Snowball (Original)
- Xapian
- 99webTools
- Reuters Web of Science™
- Function Words (Cook 1988)
- Okapi (gsl.sample)
- Snowball (Expanded)
- Galago (stopStructure)
- DataScienceDojo
Stop words lists
- CoreNLP (stopwords.txt)
- OkapiFramework
- ATIRE (NCBI Medline)
- scikit-learn
- Glasgow IR
- Function Words (Gilner, Morales 2005)
- Gensim
- Okapi (Expanded gsl.cacm)
- spaCy
- C99 and TextTiling
- Galago (inquery)
- Indri
- Onix, Lextek
- GATE (Keyphrase Extraction)
He got candy. He shouldn’t have, but he did
snowball (175)
SMART (571)
NLTK (179)
He got candy. He shouldn’t have, but he did
ISO (1298)
CoreNLP (29)
Galago (15)
Funky stop words
she's doesn’t appear in the SMART list, but he's does
fify was left undetected for 3 years (2012 to 2015) in scikit-learn
substantially, successfully, and sufficiently appears in the ISO list
Removing stop words with tidytext
Now that we have the tokens in the state we want, we might want to count them
Removing stop words with tidytext
# A tibble: 53,142 × 2
token n
<chr> <int>
1 project 5660
2 research 5112
3 study 3108
4 data 2950
5 based 2770
6 cell 2397
7 cells 2277
8 1 2083
9 studies 2007
10 development 1992
# ℹ 53,132 more rowsCounting Tokens
What to count
We can look at the words that are most different between the two years
What to count
# A tibble: 53,142 × 3
token `2012` `2022`
<chr> <int> <int>
1 project 3344 2316
2 study 1933 1175
3 cells 1487 790
4 research 2872 2240
5 analysis 1121 622
6 cell 1414 983
7 model 1085 668
8 development 1192 800
9 studies 1196 811
10 1 1226 857
11 information 841 485
12 role 992 651
13 processes 918 582
14 investigate 758 422
15 properties 775 445
16 proposed 832 504
17 function 724 397
18 system 997 683
19 understanding 1146 839
20 effects 811 511
21 proposal 645 345
22 experiments 611 314
23 soil 416 120
24 structure 636 351
25 based 1527 1243
26 expression 531 248
27 data 1611 1339
28 propose 606 336
29 mechanisms 829 562
30 activity 608 341
31 field 912 650
32 proteins 521 261
33 results 962 703
34 systems 905 647
35 specific 1071 815
36 time 1033 780
37 techniques 529 281
38 mice 386 141
39 pandemic 1 245
40 experimental 551 318
41 level 662 434
42 phase 464 239
43 functional 566 345
44 major 555 334
45 surface 442 222
46 learning 222 440
47 growth 437 219
48 public 234 451
49 3 804 589
50 involved 410 199
51 low 503 294
52 protein 534 326
53 formation 455 253
54 phd 309 107
55 process 630 433
56 performance 411 218
57 approach 817 625
58 organic 281 91
59 2 1009 820
60 control 717 529
61 test 518 335
62 recently 442 259
63 determine 435 255
64 transport 336 156
65 effect 444 267
66 mechanism 320 145
67 obtained 271 96
68 addition 409 235
69 2011 216 42
70 imaging 449 276
71 gene 386 213
72 structures 415 246
73 processing 326 157
74 genes 308 139
75 2012 211 42
76 theoretical 421 253
77 magnetic 338 170
78 genetic 407 240
79 19 16 181
80 dna 373 210
81 conditions 564 402
82 mass 304 142
83 temperature 322 161
84 developed 579 421
85 water 411 253
86 measurements 300 142
87 projects 325 168
88 investigated 261 104
89 2022 3 160
90 behavior 341 185
91 plan 364 209
92 molecular 753 599
93 cancer 467 313
94 structural 373 219
95 i.e 409 256
96 laboratory 341 188
97 quantum 293 445
98 induced 363 212
99 influence 354 203
100 2020 4 155
# ℹ 53,042 more rowsn-grams
"the bicycle" "bicycle as" "as an" "an example" "example of" "of social" "social construction" "construction cycling" "cycling in" "in eastern" "eastern europe" "europe why" "why are" "are we" "we surprised" "surprised to" "to learn" "learn about" "about its" "its history" "history micromobility" "micromobility and" "and state" "state policies" "policies bicycle" "bicycle for" "for emancipation" "emancipation and" "and as" "as a" "a means" "means of" "of totalitarian" "totalitarian control" "control how" "how does" "does history" "history cycling" "cycling in" "in eastern" "eastern europe" "europe relate" "relate to" "to other" "other global" "global phenomena" "phenomena of" "of cycling"Counting n-grams
using unnest_ngrams() allows us to get n-grams
Counting n-grams
# A tibble: 571,661 × 2
token n
<chr> <int>
1 of the 14457
2 in the 8265
3 will be 5286
4 on the 3983
5 to the 3925
6 and the 3584
7 we will 2977
8 for the 2907
9 at the 1986
10 of a 1953
# ℹ 571,651 more rowsCounting n-grams
We can remove stop words again
Counting n-grams
# A tibble: 254,139 × 4
token n1 n2 n
<chr> <chr> <chr> <int>
1 research project research project 482
2 project aims project aims 351
3 proposed project proposed project 282
4 proposed research proposed research 270
5 climate change climate change 265
6 gene expression gene expression 219
7 covid 19 covid 19 168
8 molecular mechanisms molecular mechanisms 161
9 machine learning machine learning 144
10 specific aims specific aims 141
# ℹ 254,129 more rowsGraph n-gram
Using {igraph} we can turn the data into a graph
Graph n-gram
IGRAPH 5d1f37a DN-- 148 107 --
+ attr: name (v/c), n (e/n)
+ edges from 5d1f37a (vertex names):
[1] research ->project project ->aims
[3] proposed ->project proposed ->research
[5] climate ->change gene ->expression
[7] covid ->19 molecular ->mechanisms
[9] machine ->learning specific ->aims
[11] wide ->range real ->time
[13] shed ->light single ->cell
[15] mechanisms->underlying public ->health
+ ... omitted several edgesPlotting n-gram graph
Using {ggraph} we can look at the connections of paired words
Plotting n-gram graph
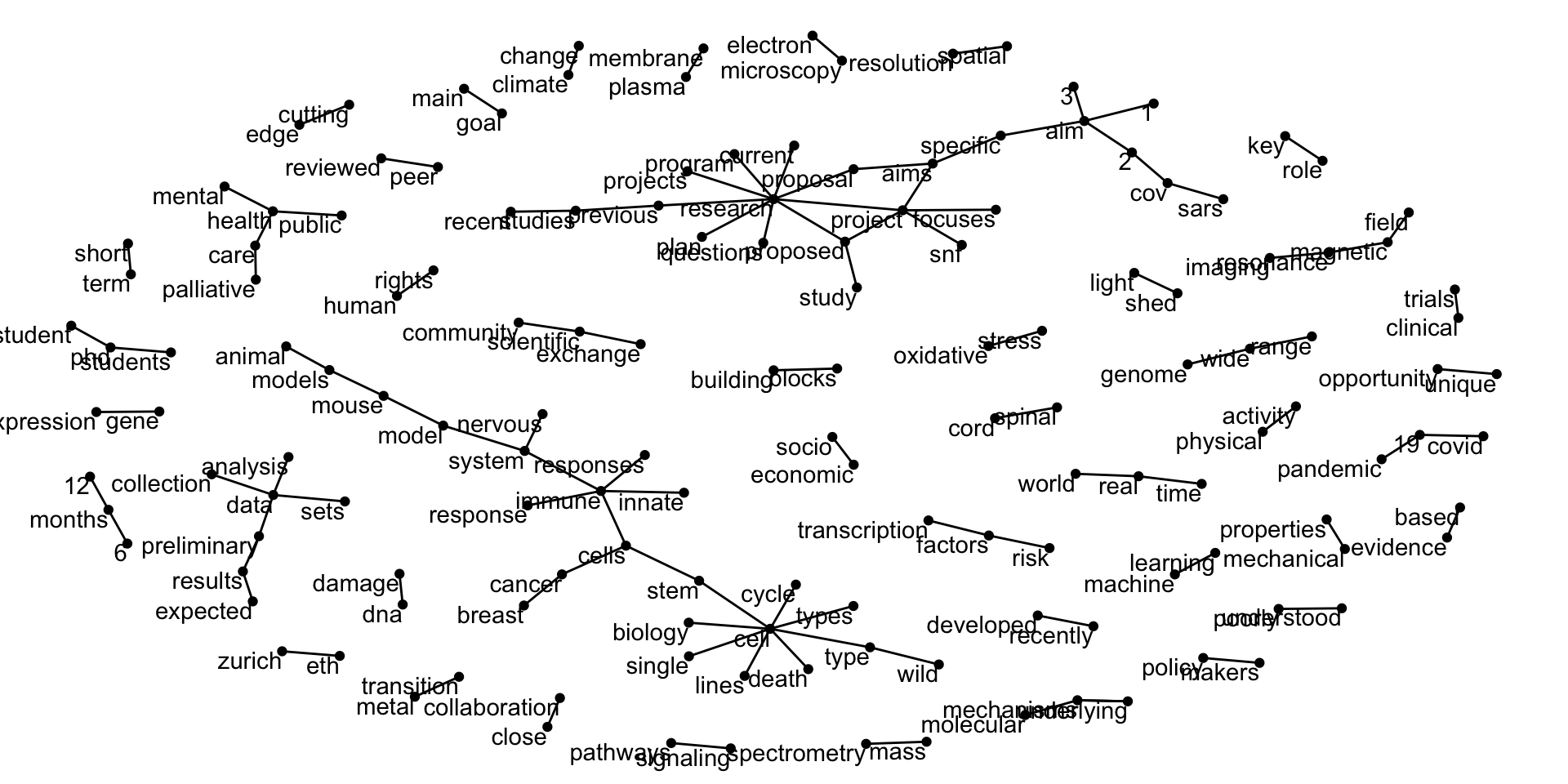
Text Mining with R
