rec <- recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_nzv(all_predictors()) |>
step_normalize(all_numeric_predictors())
rec_prepped <- prep(rec)
Flexible
feature engineering
using {recipes}
What is
feature engineering?
What are features?

Illustrations from the Openscapes blog Tidy Data for reproducibility, efficiency, and collaboration by Julia Lowndes and Allison Horst
I tend to think of a feature as some representation of a predictor that will be used in a model.
Old-school features:
- Interactions
- Polynomial expansions/splines
- PCA feature extraction
“Feature engineering” sounds pretty cool, but let’s take a minute to talk about preprocessing data.
Two types of preprocessing

Two types of preprocessing

General definitions
- Data preprocessing are the steps that you take to make your model successful
- Feature engineering are what you do to the original predictors to make the model do the least work to perform great
Some models can’t handle non-numeric data (missing data)
- Linear Regression
- K Nearest Neighbors
Some models are fine with categorical variables
- most tree based models
Some models struggle if numeric variables aren’t scaled
- K Nearest Neighbors
- Anything using gradient descent
Working with dates
Consider a datetime field. If given as a raw predictor, it is converted to an integer.
It can be re-encoded as:
- Days since a reference date
- Day of the week
- Month
- Year
- Indicators for holidays
static
- sqrt, log, inverse
- dummies with known levels
- date time extractions
trained
- centering & scaling
- Imputation
- PCA
- anything for unknown levels
Photo by Yulia Khlebnikova on Unsplash
Trained methods needs to
calculate sufficient information
to be applied again
Photo by Yulia Khlebnikova on Unsplash
Considerations
if all methods are static, they can be done ahead of time
- good for computational methods
- BERT
- bad for fast and expanding methods
- feature hashing
anything after a trained transformation needs to be done within the modeling process

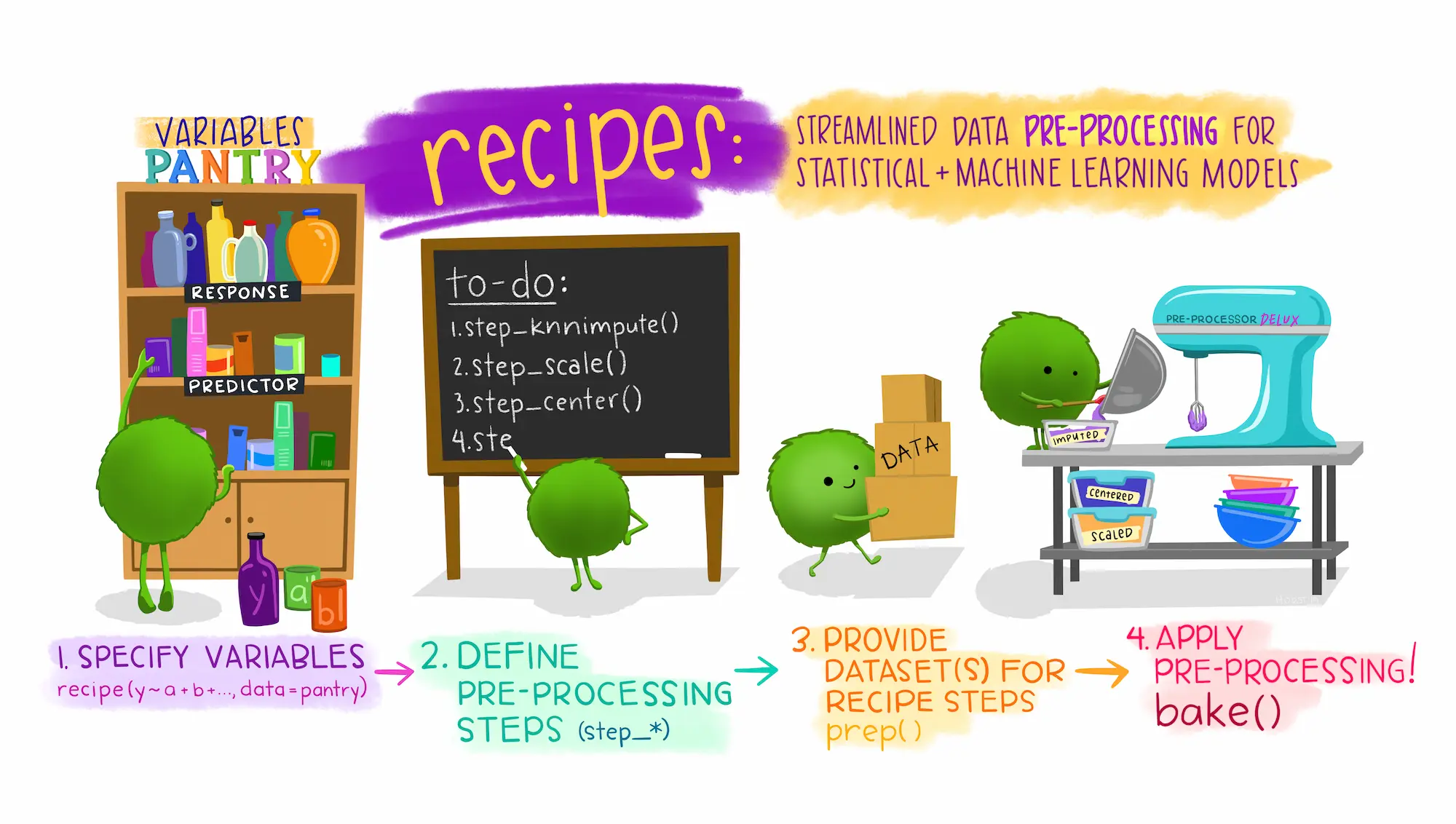
{recipes} package
extensible framework for pipeable sequences of feature engineering steps provides preprocessing tools to be applied to data
- Modular + extensible
- pipeable
- Deferred evaluation
- Isolates test data from training data
- Can do things formulas can’t
What is a recipe?
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
What is a recipe?
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
Start by calling recipe() to denote the data source and variables used
What is a recipe?
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
specifying what actions to take by adding step_*()s
What is a recipe?
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
using {tidyselect} and recipes specific selectors to denote affected variables
What is a recipe?
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
many steps have options to modify behavior
Using a recipe
rec_spec <- recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
recipes are can be used with {workflows} to “combine” it with a model
wf_spec <- workflow() |>
add_recipe(rec_spec) |>
add_model(linear_reg())
recipes are estimated
Every preprocessing step in a recipe that involved
calculations uses the training set. For example:
- Levels of a factor
- Determination of zero-variance
- Normalization
- Feature extraction
Once a a recipe is added to a workflow,
this occurs when fit() is called.
types of steps - trained
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
Levels not found in tranining data set are set to “unseen”
types of steps - trained
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
records which levels are seen in training data set
types of steps - trained
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
records which variables had zero variance
types of steps - trained
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
records mean and sd of variables
types of steps - static
recipe(sale_price ~ ., data = ames_training) |>
step_unknown(all_nominal_predictors()) |>
step_other(all_nominal_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_date(date_sold, features = c(“month”, “dow”, “week”)) |>
step_zv(all_predictors()) |>
step_normalize(all_numeric_predictors())
these steps provide static transformations, and could thus be done outside before the recipe
Artwork by @allison_horst
Extensive role selection
All steps use {tidyselect} to select variables
… |>
step_pca(BsmtFin_SF_1, BsmtFin_SF_2, Bsmt_Unf_SF,
Total_Bsmt_SF, First_Flr_SF, Second_Flr_SF,
Wood_Deck_SF, Open_Porch_SF,
threshold = 0.8) |>
…
variables can be written out one by one
Extensive role selection
All steps use {tidyselect} to select variables
… |>
step_pca(contains(“SF”), threshold = 0.8) |>
…
using tidyselect::contains()
Extensive role selection
All steps use {tidyselect} to select variables
… |>
step_pca(contains(“SF”), -starts_with(“Bsmt”),
threshold = 0.8) |>
…
or combine multiple {tidyselect} selectors
Useful selectors - tidyselect
starts_with()ends_with()contains()matches()num_range()one_of()any_of()
Useful selectors - recipes
In addition to all_predictors() and all_outcomes()
- all_numeric()
- all_double()
- all_integer()
- all_logical()
- all_date()
- all_datetime()
- all_nominal()
- all_string()
- all_factor()
- all_unordered()
- all_ordered()
all have *_predictors() variants
Tidying a recipe
We can use prep() to “train” a recipe
Tidying a recipe
running tidy() reveals the steps and basic information
# A tibble: 5 × 6
number operation type trained skip id
<int> <chr> <chr> <lgl> <lgl> <chr>
1 1 step unknown TRUE FALSE unknown_n939d
2 2 step other TRUE FALSE other_zfonZ
3 3 step dummy TRUE FALSE dummy_pdHMv
4 4 step nzv TRUE FALSE nzv_RUieL
5 5 step normalize TRUE FALSE normalize_Bp5vKTidying a recipe
you can use number or id to select a step
# A tibble: 32 × 2
terms id
<chr> <chr>
1 BsmtFin_SF_2 nzv_RUieL
2 Kitchen_AbvGr nzv_RUieL
3 Open_Porch_SF nzv_RUieL
4 Enclosed_Porch nzv_RUieL
5 Three_season_porch nzv_RUieL
6 Screen_Porch nzv_RUieL
7 Pool_Area nzv_RUieL
8 Misc_Val nzv_RUieL
9 Street_other nzv_RUieL
10 Lot_Shape_other nzv_RUieL
# ℹ 22 more rowsTidying a recipe
you can use number or id to select a step
# A tibble: 98 × 3
terms columns id
<chr> <chr> <chr>
1 MS_SubClass One_and_Half_Story_Finished_All_Ages dummy_pdHMv
2 MS_SubClass Two_Story_1946_and_Newer dummy_pdHMv
3 MS_SubClass One_Story_PUD_1946_and_Newer dummy_pdHMv
4 MS_SubClass other dummy_pdHMv
5 MS_Zoning Residential_Medium_Density dummy_pdHMv
6 MS_Zoning other dummy_pdHMv
7 Street other dummy_pdHMv
8 Alley other dummy_pdHMv
9 Lot_Shape Slightly_Irregular dummy_pdHMv
10 Lot_Shape other dummy_pdHMv
# ℹ 88 more rowsExtension packages
Extension packages
Provides steps to handle text variable
- tokenization
- filtering
- counting
Extension packages
Advanced methods to embed categorical and numeric variables to smaller vector spaces
- weight of evidence
- string collapsing
- PCA variants
Extension packages
Steps to deal with imbalanced data
- up and down-sampling
- SMOTE variants
- ADASYN
Extension packages
Time based methods
- time series signatures
- lags & diffs
- smoothing
Thank You!
read more at recipes.tidymodels
Photo by Brooke Lark on Unsplash